
What Data Analysts Can Learn From the Success of Non-Original Movies and Shows For Data Modelling
6 min read

As mentioned in my post Strive to Be The Beatles of Data Analytics, Not Beethoven - How to Apply the K-I-S-S Principle in Data Analytics, often simple solutions are the better, especially faster, options for solving business problems.
One simple approach is just taking something that is already out there and tweaking it so it fits. This has been done in the film industry for years now - with great commercial success. In data analysis this means instead of trying to apply a complex deep learning algorithm to the seemingly unique distribution of business data, just take an already existing distribution with only a few parameters.
The Success of Non-Originality
Are you also a big movies fan like me? Or love watching shows? And have you also noticed that there is less original content being released?
For clarification: non-original content “is a film or TV show that is based on or derived from any previous material, such as books, comics, sequels, prequels, trilogies, spin-offs, remakes, reboots, adaptations, etc.” (The Rise of Non-Original Content: How Hollywood is Running Out of Ideas, medium.com)
Most recent examples are Deadpool & Wolverine, Oppenheimer (biopics are basically adaptations), Wednesday.

{kind=link}
{kind=link}
Speaking of biopics: while researching for this post I noticed that there are only very few biopics about women. Of course this is saying more about our history than the film industry. So here are some recommendations:
Hidden Figures
Erin Brockovich
The Favourite

{kind=link}
{kind=link}
{kind=link}
If these films are so “unoriginal”, why is the share of non-original content increasing every year? In 2000, the share of American non-original films was already at 59.1%, and is now at 81.4%. For TV shows, that’s 33.3% in 2013 and 61.5% now (Netflix & Hulu). (The Rise of Non-Original Content: How Hollywood is Running Out of Ideas, medium.com)

The reason is simple: just as any company, the film industry “is a risk-averse industry. […] A well-known title, no matter how dated, is still a safer bet than an unknown property in financiers’ eyes.” (Gen Z just said it’s sick of remakes. Here’s why that’s bad timing for Hollywood, fastcompany.com)
Non-original doesn’t mean bad. Film and show makers still invest a lot of money and resources, as there is so much more to a successful production than just the story idea.
The advantage of using existing material is that there is more time to tweak it in a way that’s suitable for film, the audience, the current zeitgeist.

Non-Originality in Data Analytics
As mentioned companies are risk-averse. Their aim is usually to solve business problems fast and well - not perfectly.

{kind=link}
The Wolf of Wall Street, one of the most successful biopics, is a good example for such a solution: the story is already crazy enough for a film to engage audiences. Put on top some famous names (Martin Scorsese, Leonardo DiCaprio, Jonah Hill, Margot Robbie), and success is very likely.
It’s counterpart in data analytics? Any already known statistical distribution, e.g. binomial distribution, Pareto distribution.
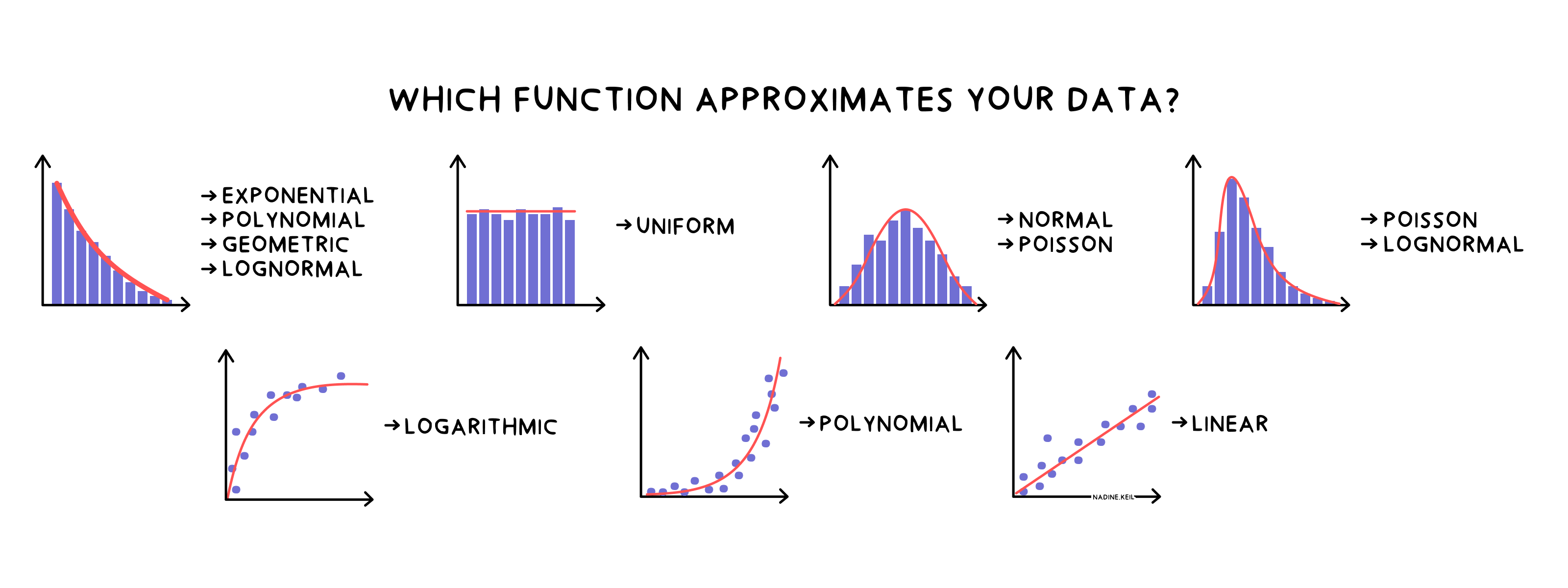
The biggest challenge with data is modelling the underlying distribution. How will customer behaviour change over time? How does it correlate with pricing or certain products?
Nowadays, data analysts and data scientists try to solve these kind of problems with machine learning or even deep learning algorithms. Those methods don’t require any assumptions about the data’s distribution. They “just” approximate it from the data. Well, “just” is an understatement. They require a lot of understanding of the input data: its quality, completeness, variance, correlation. The models are complex, so a lot of time needs to be spent on adjusting them correctly.
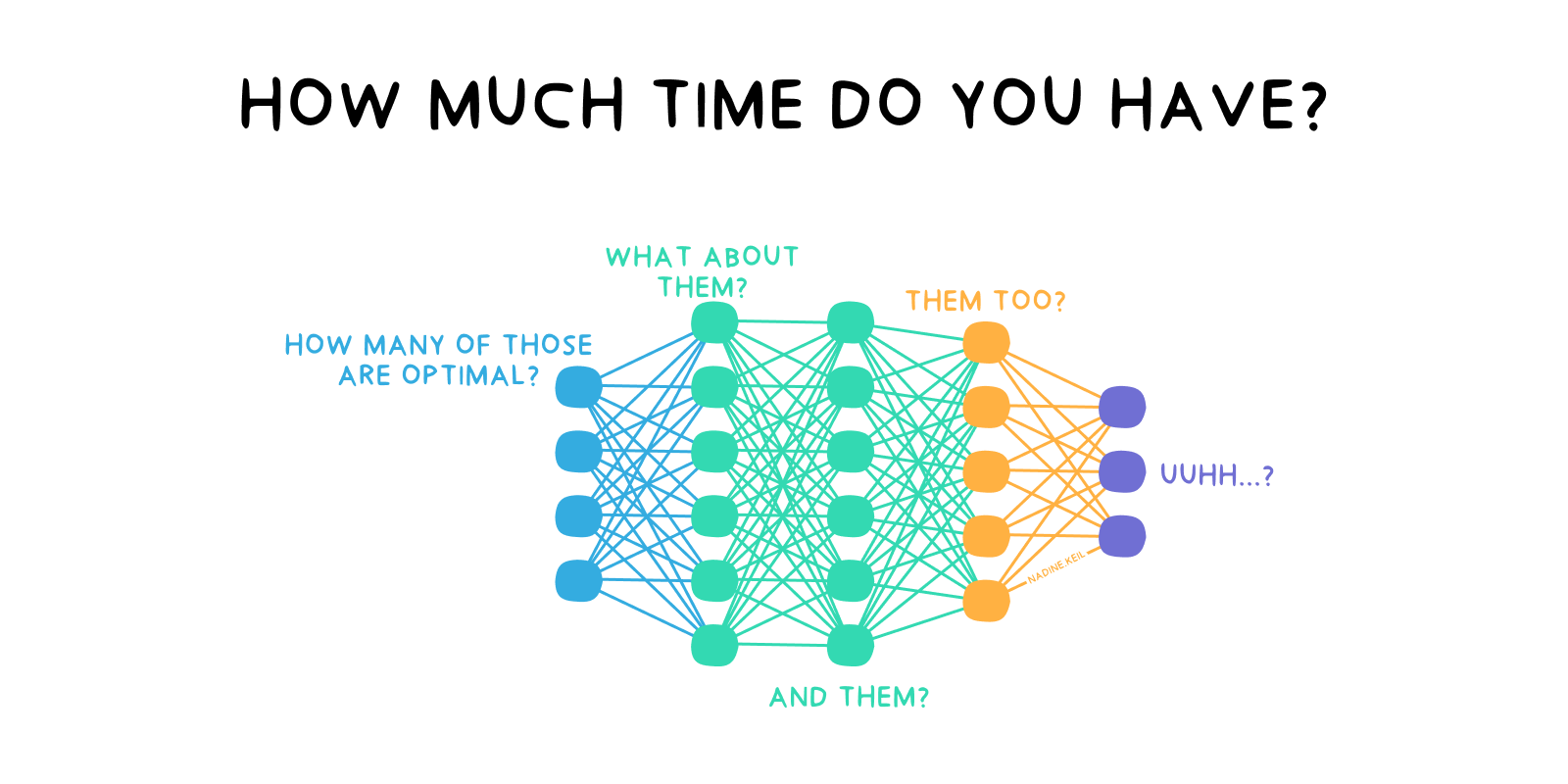
Those models are comparable to original movies like “Everything, Everywhere, All At Once” - released in 2022, “it became A24’s highest-grossing film and garnered widespread critical acclaim.” (en.wikipedia.org) Still it wasn’t among the Top 10 Highest Grossing Films that year, nor the week after (en.wikipedia.org). That list consisted entirely of non-original films, mostly sequels.

{kind=link}

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Conclusion
If you want to solve business problems fast and with less risk, rather opt for simple statistical methods. Visualise your data and make assumptions about which existing distributions would be a good fit. Invest the time to tweak those models so that they work with your specific data.
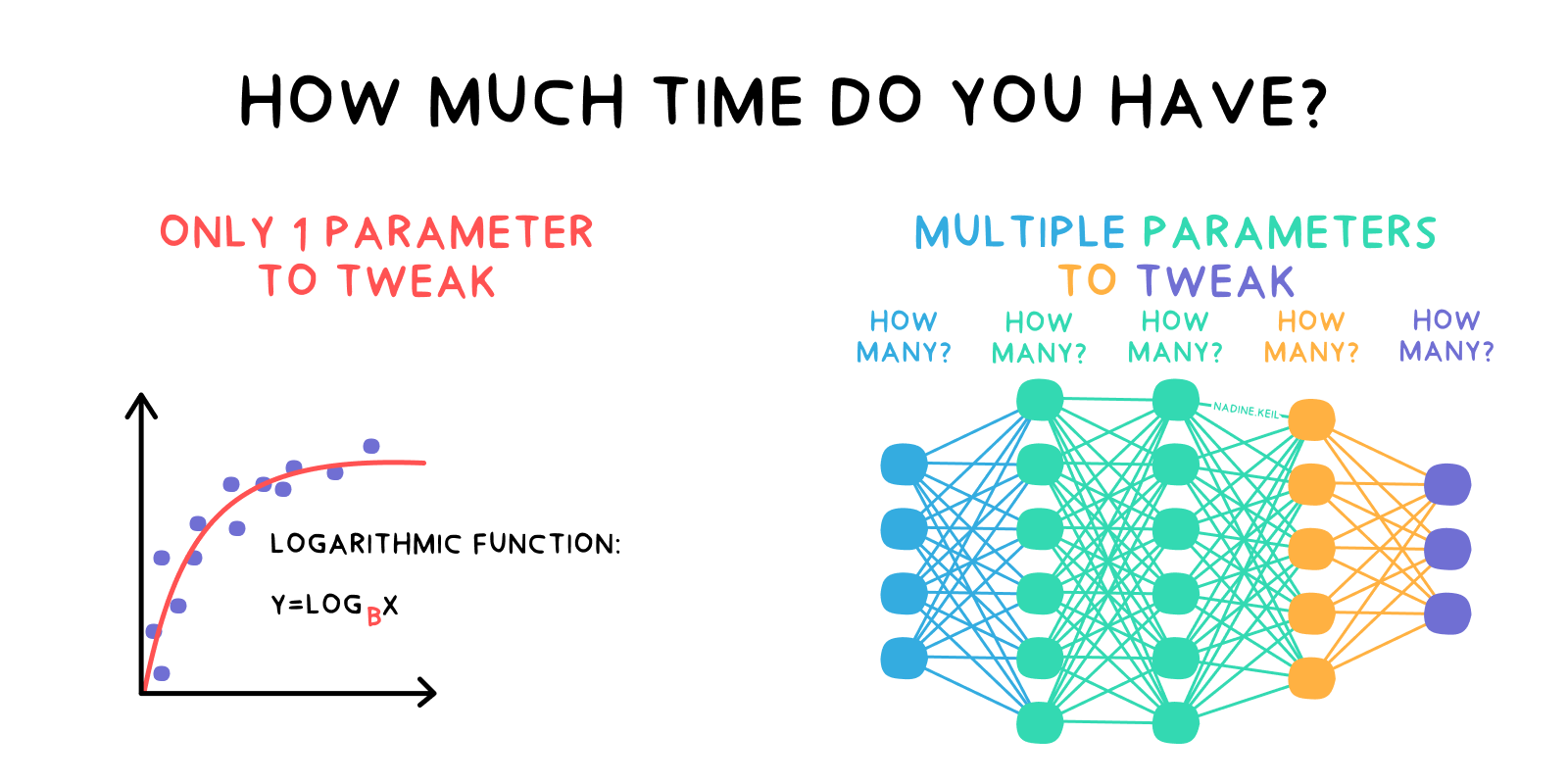
Most of the data influenced by customer behaviour is changing constantly anyways, mainly due to macroeconomic circumstances, which are out of a company’s control. So it’s important to stay flexible and adapt quickly.
If you have time to experiment and want a more robust model for the long-term, then go ahead and create the next original production.
Which type of movies or shows do you prefer - original or non-original?
Hi, I'm Nadine. I empower people through comprehensive training and coaching in data analysis and mathematical modeling, equipping them with the tools and knowledge to excel professionally. If you’re interested in finding out how I can support you in your learning journey, book a free 30-minutes introduction call with me right here, send an email to nadine@mathemalytics.com, or connect with me on LinkedIn.
👏